

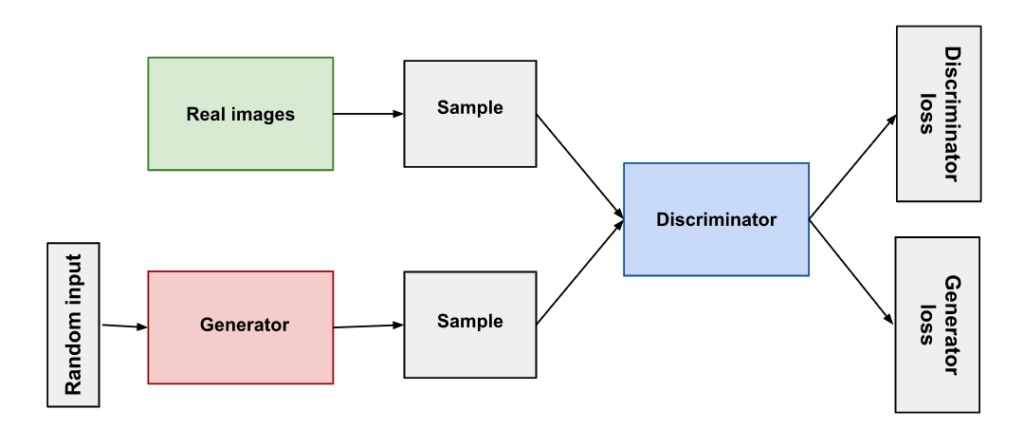
The discriminator in Generative Adversarial Networks (GANs) has a crucial role, acting as a classifier to distinguish between genuine and fabricated samples. A perfect discriminator assigns a probability of 1 to true samples and 0 to fake ones. However, this ideal scenario can lead to a challenging problem known as the vanishing gradient problem. In this situation, the generator’s training lags behind the discriminator’s, as the latter excels in its classification task. As a result, the discriminator’s loss function gradient approaches zero, preventing the generator from updating its loss effectively.
To address this issue, researchers introduced Wasserstein GAN (WGAN) (Arjovsky et al., 2017), a significant advancement in the field. WGAN redefines the discriminator’s task as a regression problem, utilizing the Wasserstein distance (earth mover’s distance) to measure the distribution distance between real and fake samples. By training the discriminator to completion, it offers a near-perfect loss function to the generator, alleviating the vanishing gradient problem and enhancing training stability.
Moreover, WGAN proved to be resilient against mode collapse, a prevalent issue where the generator gets stuck in a limited region of the real-data distribution, leading to repetitive and non-diverse outputs. This resilience further cemented WGAN’s effectiveness as a discriminator model in GANs.
Building upon the success of WGAN, a later variant called WGAN-GP (Gulrajani et al., 2017) incorporated a gradient penalty to provide even more stable training. With this improvement, GANs using WGAN-GP as their discriminator model achieved better performance and more reliable convergence.
In conclusion, the advancements in GAN discriminator models, from addressing the vanishing gradient problem with WGAN to enhancing stability with WGAN-GP, have significantly contributed to the progress of Generative Adversarial Networks and their ability to generate high-quality and diverse samples.







